Table of contents
Abstract
- introduce a concept of using zero shot in computer vision
- take nlp paradigm to computer vision
Method
(1) Contrastive pre-training
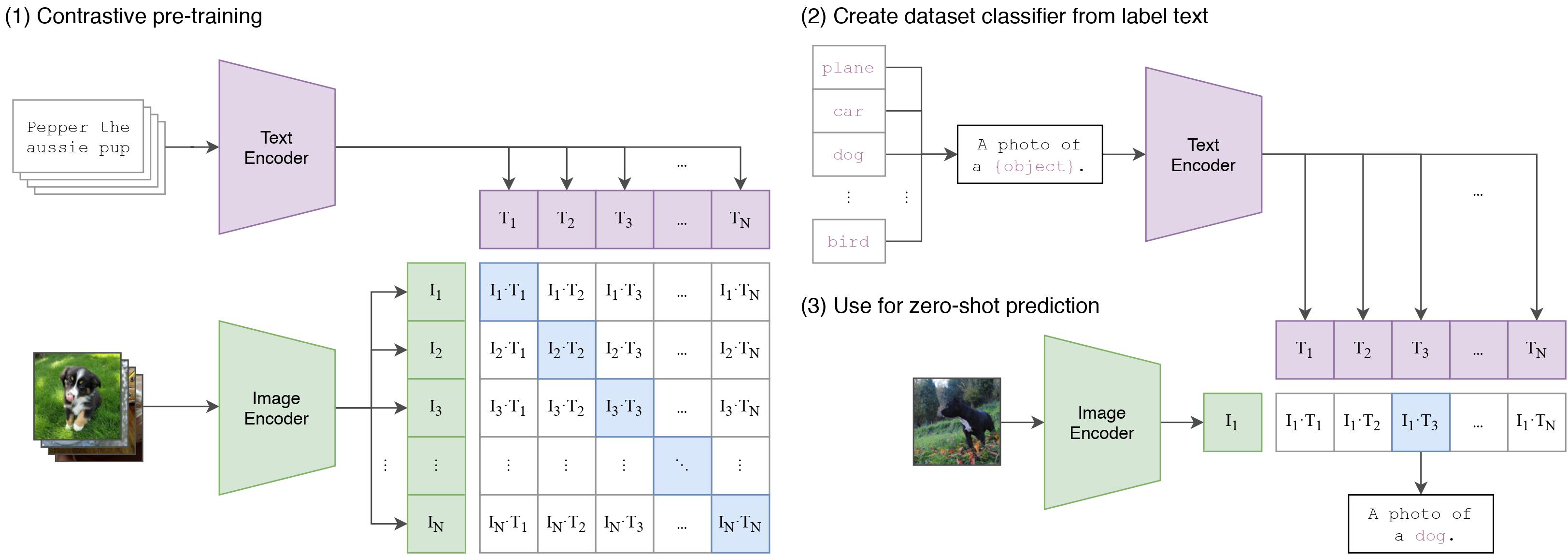
- Associated with they image/text pairs
- Image Part
- data augmentation
- Image Encoder : ResNet and vision transformer
- get certain representation at the output
- Linear Projection and finally inside contrastive embedding space
- Text Part
- Text Encoder : Vaswani transformer
- embed text sequence here
- Layer Normalization and use linear projection layer into the embedding space
- Text Encoder : Vaswani transformer
Linear Projectoin Layer를 통해 embedding space를 contrastive embedding space로 가져옴
\[{<} I_i,T_i {>} = \begin{cases} 1, & \text{if i==j} \\ 0, & \text{ow.} \end{cases}\]over the row
\begin{equation}
l_i^{v \rightarrow u} = - \log\frac{\exp{<} v_i,u_i {>}/\tau)}{\sum_{k=1}^{N}\exp{<} v_i,u_i {>}/\tau} \end{equation}
\tau : temperature coefficient, just modifies the softmax distribution to make it a bit more steep familiar softmax : sum of all of I_1,T_i and get the probability distribution -log : cross entropy loss over that softmax distribution
over the column
\begin{equation}
l_i^{v \rightarrow u} = - \log\frac{\exp{<} u_i,v_i {>}/\tau)}{\sum_{k=1}^{N}\exp{<} u_i,v_i {>}/\tau} \end{equation}
Final Loss Vector weight combination of those two and sum over the whole batch and avg \begin{equation} L = \frac{1}{N}{\sum_{i=1}^{N}(\lambda l_i^{v\rightarrow u}+(1-\lambda)l_i^{u\rightarrow v}}) \end{equation}
(2) Create dataset classifier from label text
- SimCLR
- only random cropping as data augmentation $\rightarrow$ most patches from an image share a similar color distribution
- model can learn to cheat by just looking at the histogram distribution and figure out those are the same instance
- even though they are visually different, the histograms are the same so it will be really easy problem to just place them in the same part of the embedding space
- with color jitter : model can’t explain this trick
- random crop + random color jitter 사용
How did they use it in a zero shot setting
Text Encoder : pre-trained 1) embed those classes in sentences “A photo of a {class}” 2) encode those sentences in the same way with pre-trained Text Encoder 3) with text encoder we can dispatch of embeddings
Use for zero-shot prediction
1) take image that we want to get classified 2) find it’s embedding vector 3) do simple cosine similarity between I embedding vector and T embedding vector 4) high similarites -> our class
Q. 이 논문을 어떻게 이용할 수 있을까
Q. 참고하고 싶은 다른 레퍼런스