본 포스트는 Dream AI Smart Device Hackathon LG Challenge에 참가하며 수행한 과제 내용을 기반으로 작성되었습니다. 과제는 1라운드 - 팀별 가짜 이미지 생성, 검출 모델 성능 경쟁 / 2라운드 - 기술사업화 PT 경쟁으로 진행되었습니다. 가짜 이미지 생성 및 검출 과제를 수행하며 Generative Adversarial Network의 동작 방식을 더 잘 이해할 수 있었고 향후 연구를 진행하는데 많은 도움을 받을 수 있었습니다.
Table of contents
과제수행 전략
본 과제를 수행하기 위해 다음의 전략을 취했습니다. 첫째, 현재 사용가능한 state-of-the-art 모델을 조사였습니다. 둘째, 가짜 이미지 생성에 있어 사용자의 의도대로 이미지 생성 및 조작이 가능한 모델을 알아보았습니다. 셋째, 특정 생성모델에 편향되지 않고 일반적으로 사용가능한 검출기를 구현하려 노력하였습니다.
생성기의 경우 가상비서 서비스가 취약할 수 있는 이미지들을 잘 만들어내야 한다고 판단했습니다. 새로운 가상의 인물 뿐만 아니라, 실존하는 인물에 변형을 가한 fake 이미지 역시 생성해 낼 수 있는 모델을 조사했고, 그 결과 “Adversarial Latent Autoencoders”을 Key Paper로 선택했습니다.
사람의 얼굴을 인식하여 개인화 서비스를 제공하는데 필요한 검출 기술의 핵심 요구사항으로 신뢰성과 계산 부하, 검출 속도를 선택했습니다. Fake 이미지 검출 기술은 개인화 서비스가 사적인 정보를 적극 활용한다는 점에서 fake 이미지를 통한 이용자 사칭에 안전함이 보장되어야 하고, 수시로 사용되기 때문에 계산이 너무 무겁지 않아야 하며, 매끄러운 사용자 경험을 제공하기 위해서 충분히 빨라야 합니다.
이에 저희 팀은 CVPR 2020 oral presentation에 나온 “CNN-generated images are surprisingly easy to spot… for now” 논문을 검출기의 Key Paper로 잡았습니다. 이미지 합성 과정에서 필수적으로 사용되는 Convolution Neural Networks의 흔적을 추적하는 본 논문은, Generation Model의 구조적인 한계를 공략하는 방식으로 저희가 선택한 핵심 요구사항을 만족시키는데 적합하다고 판단했습니다.
Image Generation
“중요한 스타일 정보를 더 효과적으로 학습”
Style 중요도에 기반한 새로운 Adversarial Autoencoder 구조 제시
1.Introduction
좋은 디텍터를 검증하기 위해서는 실제같은 fake 이미지를 생성할 수 있어야 합니다. 얼굴 인식 보안 검출기에 대한 분별력을 가지는 생성기는 적은 이미지 데이터로부터 다양한 고화질의 fake 이미지를 만들 수 있어야 합니다. 얼굴 인식 보안의 경우 잠재적 피해자의 데이터로부터 만든 fake 이미지를 잘 검출해야 하기 때문입니다. 이에 적은 데이터만으로도 (1) 고해상도의 실제 사람과 같은 이미지와 (2) 얼굴의 특정 부분을 미세조정한 이미지를 생성 할 수 있는 “Adversarial Latent Autoencoder”를 Key Paper로 선택했습니다.
2.method
논문에서는 기존 GAN의 네트워크 구조와 Auto-Encoder를 결합하여 Style-Controllable한 고해상도 이미지 생성을 목표합니다. 목표를 달성하기위해 제안한 방법은 다음과 같습니다.
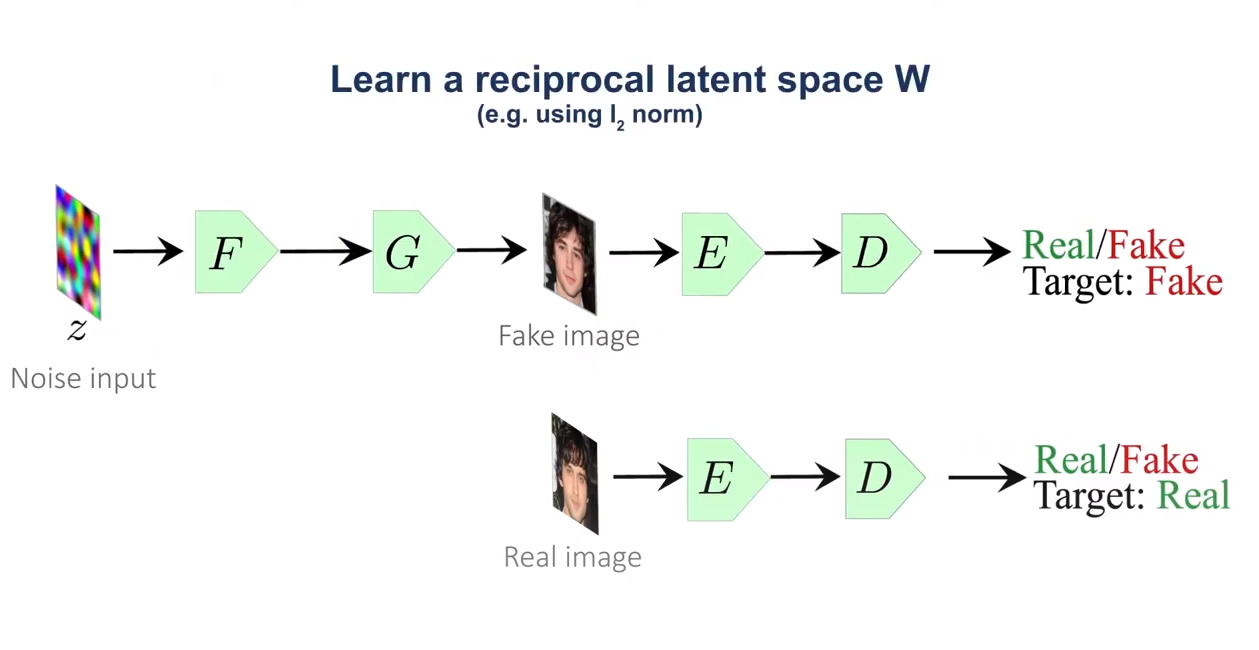
첫째, 네트워크간 결합을 통해, 기존 구조들이 가지는 한계점을 극복했습니다. 생성 모델의 주류를 이루고 있는 Generative Adversarial Networks 구조에는 고해상도 이미지 생성에 강점이 있지만, 학습 불안정성, Style-Control에는 어려움이 존재합니다. 또한 원본과 유사한 data를 만드는데 목적을 두고 있는 Auto-Encoder 구조는 입력 데이터의 특징 추출을 잘하는 반면, Mean Square Error를 loss function으로 사용함에 따라 흐릿한 이미지를 생성하는 단점이 존재합니다.
논문에서는 real 이미지를 Auto-Encoder에 통과시켜 의미적으로 중요한 특징(머리, 눈, 코, 입)들을 추출하고, 이를 GAN과 공유하여 두 네트워크가 동일한 특징 공간을 가지도록 유도했습니다. 그 결과 GAN은 가짜 이미지를 만들어내는데 필요한 특성을 잘 파악하였고 완성도 높은 고해상도 이미지를 생성할 수 있었습니다.
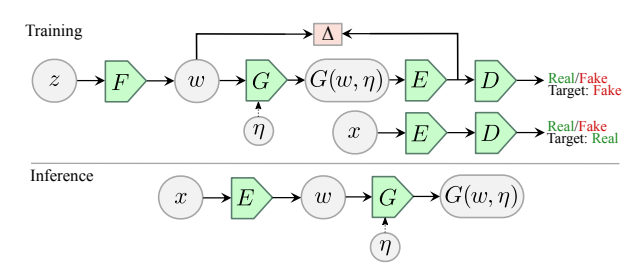
둘째, 네트워크가 Real 이미지의 Style 특징을 더 효과적으로 파악하기 위해 Generator와 Discriminator를 세분화 하였습니다. Generator의 경우, GAN이 만들어내는 Latent vector를 model에 바로 사용하는 것이 아닌 Mapping Network(StyleGAN의 아이디어)를 통과하게하여 사람 얼굴의 시각적 특징을 변경하는데 제약이 없도록 하였습니다. 생성 모델이 training data의 확률 분포를 따르지 않고 Mapping Network의 Nonlinearity를 거치게 함으로써 내가 원하는 Style만 조절하여 이미지를 생성할 수 있도록 하였습니다. Discriminator의 경우, 최종 생성된 가짜 이미지가 사전에 Encoding과정을 거치게 함으로써 Real data가 가지는 잠재 공간과 유사한 특성을 가지도록 하였습니다.
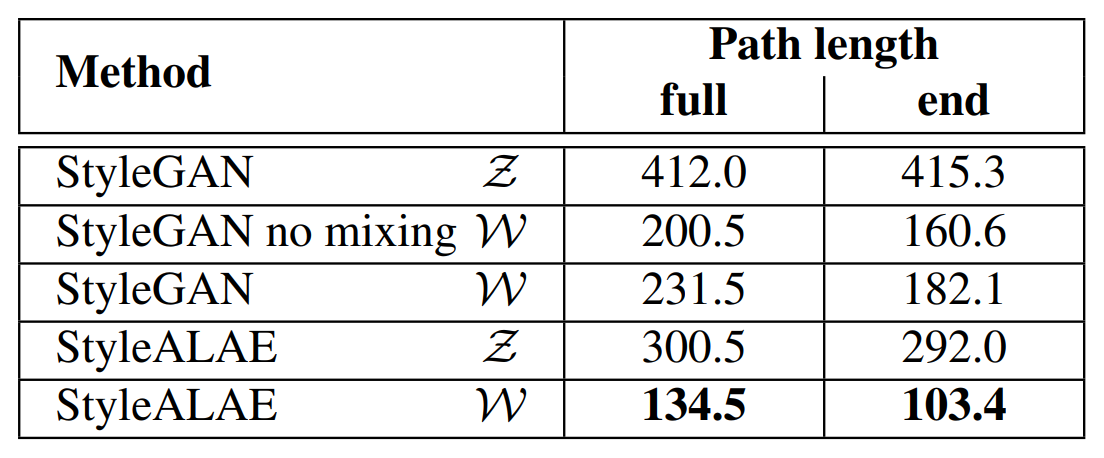
잠재 공간에 Embed되는 Style의 다양성을 측정하기 위한 Metric으로 Perceptual Path length를 사용하였습니다. 실험 결과, 기존 StyleGAN이 표현할 수 있는 Path length보다 더 낮은 수치를 보이며 StyleGAN보다 더 많은 Style feature를 표현할 수 있음을 보였습니다.
3.Conclusion

위 실험을 통해 Adversarial Latent Autoencoder가 적은 양의 데이터만으로 이미지가 가지고 있는 사람의 시각적 특징을 잘 살려 실제 사람과 같은 이미지를 잘 생성하는 것을 확인 하였습니다. 또한 ALAE는 image generation, image reconstruction, style mixing 등 다양하고 간단한 방법으로 fake 이미지를 생성 할 수 있고, 현재 Detection 모델들이 검출하기 어려워하는 고화질의 fake 이미지를 만들기 때문에, 얼굴 인식 기술이 풀어야 할 과제로서의 가치를 지닌다고 판단하여, ALAE를 저희의 최종 generation model로 제안했습니다.
Image Detection
“범인은 반드시 흔적을 남긴다” Convolution Neural Network의 Artifacts를 이용한 가짜 이미지 감지 기술
1.Introduction
가짜 이미지를 식별하는 Image Forensics 분야에서는 generalization 을 문제 해결의 핵심요소로 다루고 있습니다. 최근 CVPR에 발표된 Fake Detection 연구(Detecting and Simulating Artifacts in GAN Fake Images. In WIFS, 2019)에 따르면, 특정 Generation Architecture에 학습된 classifier가 다른 model의 가짜 이미지를 파악하는데 취약하다는 사실을 밝혀낸 바 있습니다.
2.method
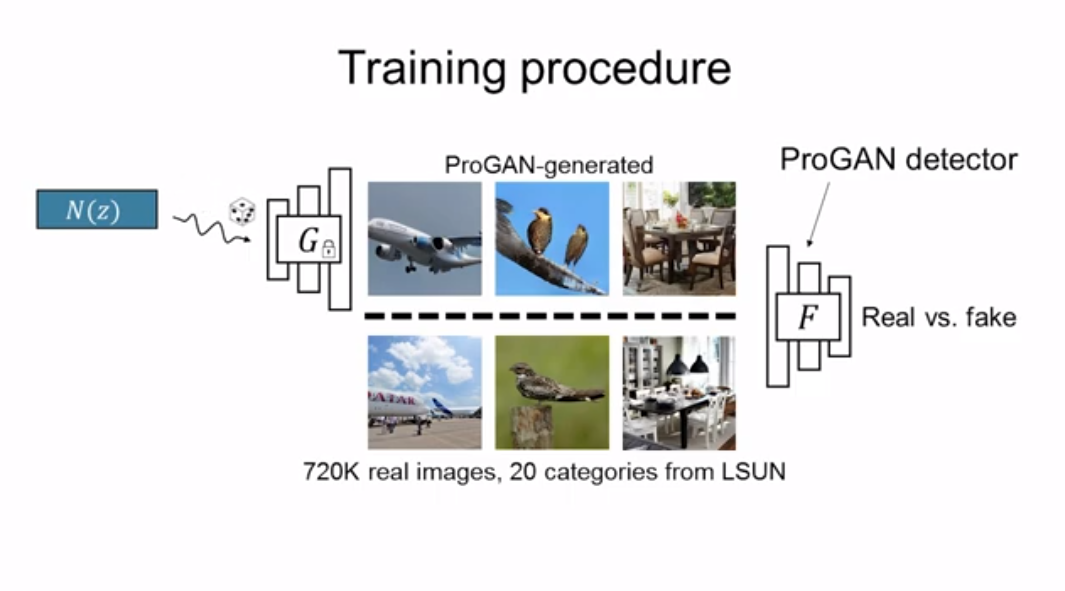
오직 한장의 이미지를 가지고 진위 여부를 가려야하는 Detector는 특정 모델에 편향되지 않으면서 다양한 공격에 유연하게 대처할 수 있어야 합니다. 논문의 저자는 CNN으로부터 합성된 이미지들은 일관된 결함을 갖고 있음을 밝히고 그러한 결함들이 간단한 classifier로 검출할 수 있다고 제안하고 있습니다. 특히, 단 하나의 특정 Generator에 대해서만 학습된 Detector를 오직 Artifact 이미지와 Real 이미지를 구분하는 Task에만 전념시킬 경우, 가짜 이미지에 대해서 매우 일반화가 잘 된다는 것을 보여주었습니다
논문에서는 Model의 Architecture가 가장 단순한 ProGAN의 Detector를 이용하여 72만개의 이미지(LSUN dataset)를 추가 학습시켰습니다. 이후 11개의 Image Generation 모델(ProGAN, StyleGAN, BigGAN, CycleGAN . . .)에서 만든 fake 이미지를 가지고 Evaluation 과정을 진행하였고 아래와 같은 정확도를 보였습니다.
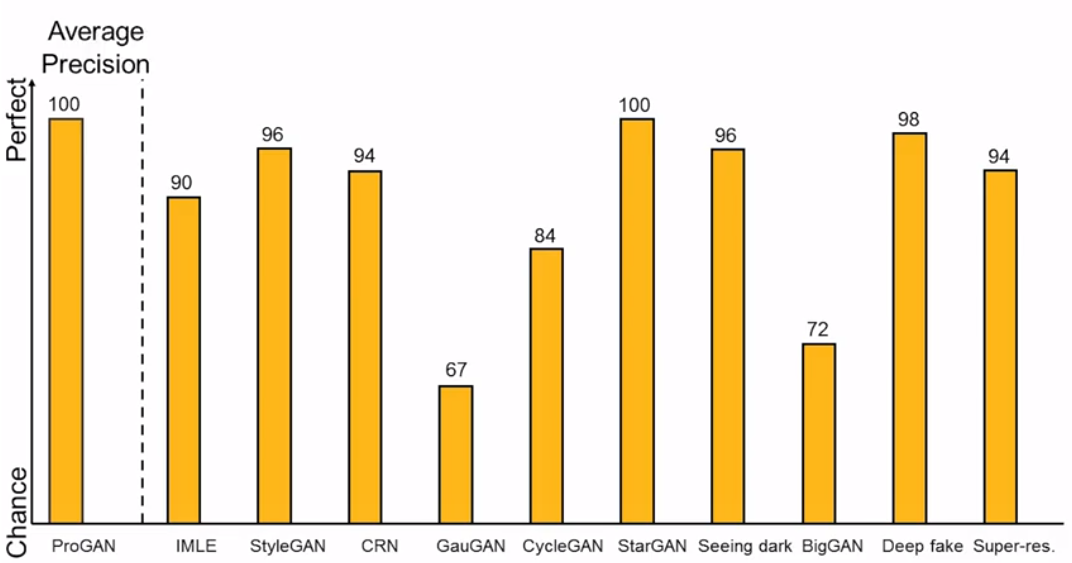
CNN의 Artifacts를 이용한 Detection 방식은 여러 Generation Model에서 90% 이상의 높은 감지율을 보이며 보편적으로 사용가능한 Detector의 가능성을 보여주었습니다. 하지만 일부 모델(GauGAN, CycleGAN, BigGAN)에서 보여주고 있는 낮은 정확도는 여전히 신뢰성의 문제를 제기하였습니다.
논문에서는 문제 해결의 실마리를 Data Augmentation에서 찾았습니다. Data Augmentaion 기법은 딥러닝 모델을 충분히 훈련시키는데 필요한 데이터를 확보하는 기법으로, 원본 데이터를 부풀려서 모델의 성능을 더 좋게 만드는 방법입니다. 저자는 ProGAN의 Detector를 train하기 위해, 원본 data에 Random Blur와 JPEG Compression 작업을 각각 50% 확률로 적용하여 추가적인 데이터를 확보하고 이를 학습에 적용하였습니다. 그 결과, 7개의 모델(IMLE, StyleGAN, CRN . . .)에서 93%~100%의 매우 높은 정확도를 보였으며 1개의 모델(BigGAN)에서 88%의 높은 정확도를 보였습니다.
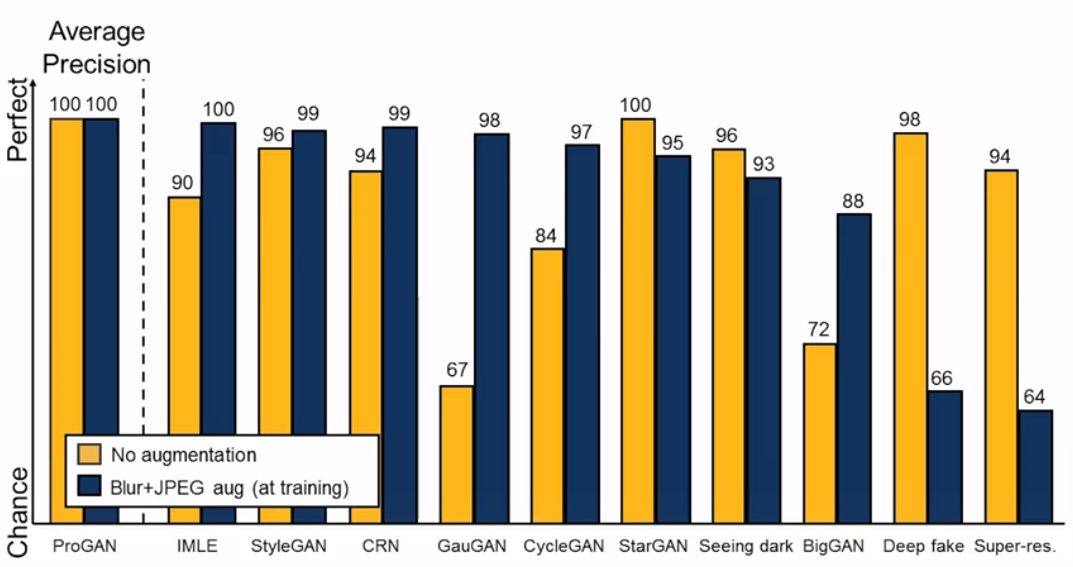
3.Conclusion
저희 팀이 다룬 CNN의 Artifacts을 이용한 가짜 이미지 탐지 방식은 다수의 네트워크 Architecture에서 우수한 인식 성능을 보이며 generalized detector의 가능성을 시사했습니다. 모델의 우수성을 검증하기 위해 추가 진행한 실험에서도, 최신 Generation Model(StyleGAN2)을 성공적으로 검출해냄에 따라 새로운 모델에도 높은 확률로 정확한 검출이 가능함을 보였습니다.