Table of contents
Abstract
- NIPS’19 Spotlight에 발표된 Normalization 기법
- 기존 Normalization Method들은 Spatial Dimension을 거쳐 Normalize를 진행하고 Feature Statistic을 버림
- PONO는 채널축에 따라 Pixel Position별 Feature 정규화를 진행하여 Structural 정보를 활용
- Generative Networks에서 Encoding시 획득한 Feature Statistic을 Decoding시 이용하여 네트워크가 Structural한 정보를 쉽게 파악하도록 도움
Normalization Method
Feature Block
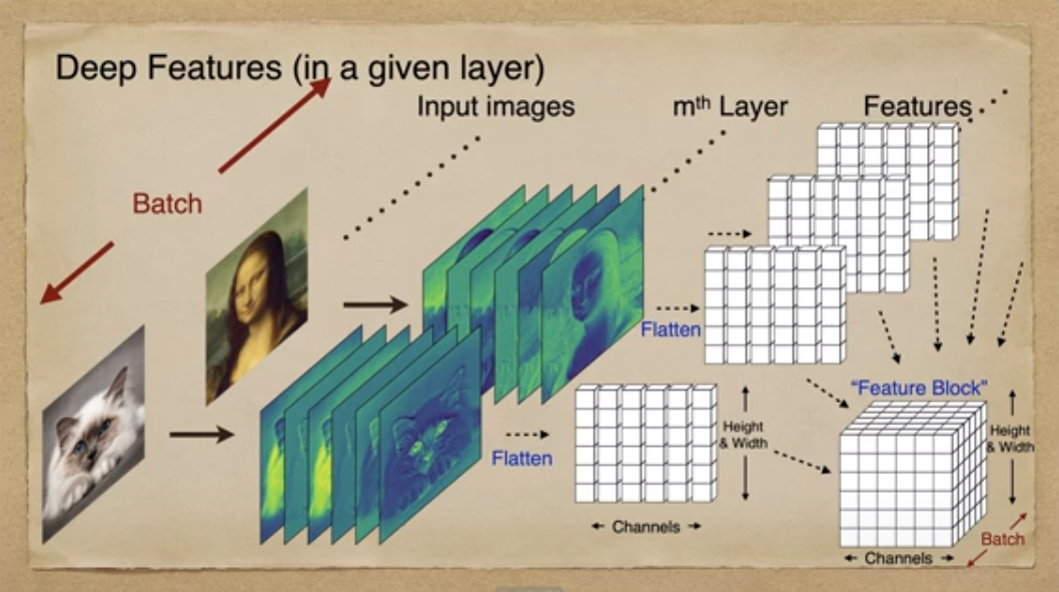
정규화 기법을 이해하기 위한 배경 지식으로 Feature Block에 대해 설명합니다. 고양이 이미지가 하나의 Layer를 통과할 때, 6개 Feature를 얻었다고 가정합니다. 각 채널별 Feature 이미지를 1D-Array로 Flatten시켜 6개의 1D-Array를 갖습니다. 여기서 하나의 열은 해당 채널의 Feature 이미지를, 행은 Feature 이미지별 같은 Position을 나타냅니다. 채널별 Feature Array를 모아 Matrix로 바꾸고 이를 Batch 단위로 쌓아 최종 Feature Block을 만듭니다.
Normalization Variants
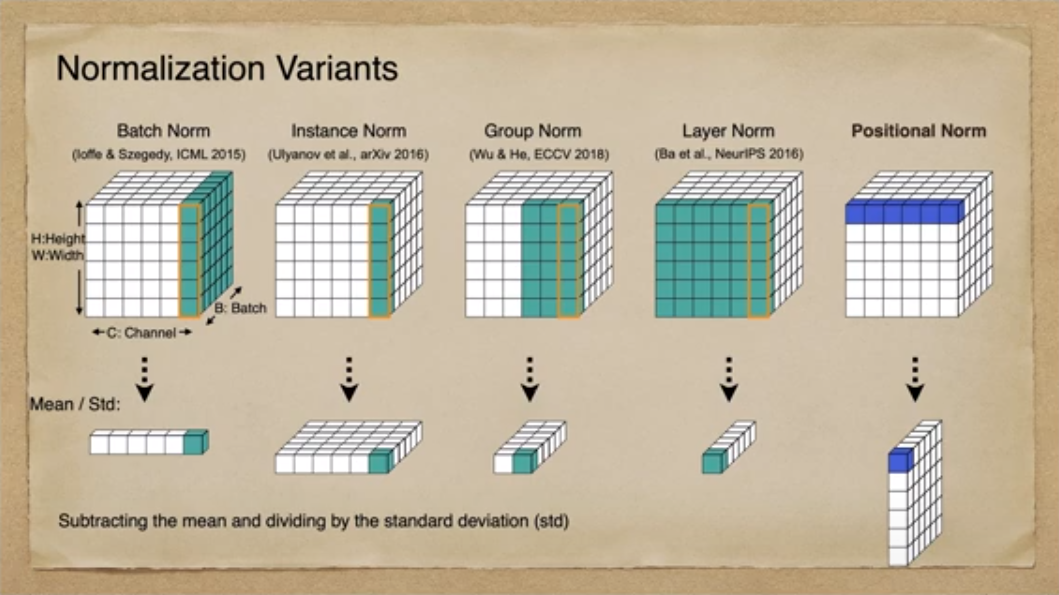
이미지 생성 분야에서 Batch Normalization의 경우, Batch 단위로 Normalize가 이뤄지기 때문에 Domain별 Style이 뭉뜽그려져 학습되는 문제가 발생하였습니다. 반면, Instance Normalization의 경우, 이미지별 feature statistics를 직접 normalize함으로써 style variation을 제거하는 효과를 가져왔습니다. 그 결과, Style Transfer 분야에서 Batch Normalization을 대체하는 모듈로 활발히 활용되었고 content의 structure를 잘 유지하면서 좋은 성능을 낼 수 있었습니다. Group Normalization과 Layer Normalization의 경우, 채널을 같이 Normalize하여 채널간 유기적인 정보를 보존해야할 때 유용히 사용되었습니다. 하지만 이전 Normalization Method의 경우, 모두 Pixel Position을 가로 질러 정규화를 수행하였고 그 결과 위치정보가 사라진 결과를 낳았습니다. Positional Normalization은 Pixel position별 Feature 차원의 정규화를 수행한 기법으로 Feature statistic의 유의미한 Structural한 정보를 남길 수 있게 되었습니다.
Positional Normalization
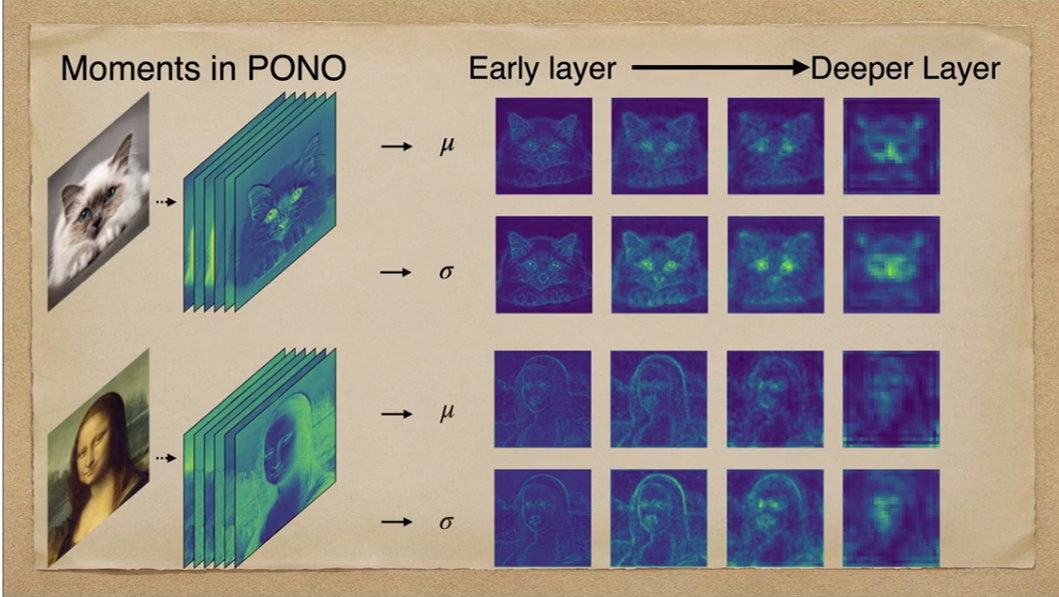
Positional Normalization 적용시 네트워크가 성공적으로 이미지(고양이, 모나리자)의 General한 Structure를 포착한 것을 확인할 수 있습니다. 특히 초기 layer에서는 눈과 귀같은 이미지의 details한 부분들을 포착해내고, 후기 layer에서는 전반적인 shape를 포착한 것을 알 수 있습니다.
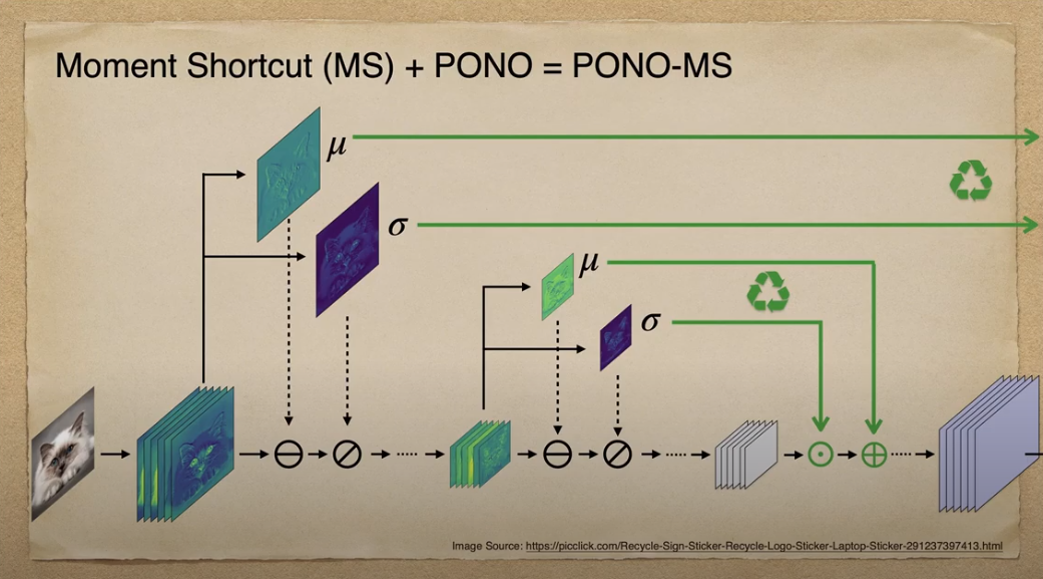
기존 Normalization Method의 경우 Encoding 단계에서 구한 Feature Statistics이 사용되고 버려지나, Positional Normalization에서는 해당 정보를 Decoding시 다시 활용하여 GAN이 Structural한 정보를 더 쉽게 복원하도록 도와주었습니다.
Experiments and Analysis
FID of CycleGAN and its variants
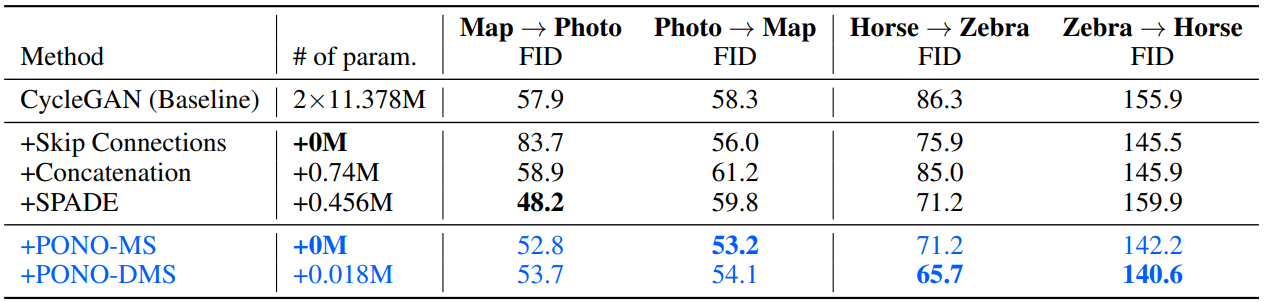
- PONO가 SPADE의 Photo->Map 상황을 제외하고 모든 경우에서 성능 향상을 보였습니다
- SPADE의 경우, Input layout을 지속적으로 사용하는 것이 structural 정보를 복원하는데 방해가되어 성능이 저하됐습니다.
- Skip Connections의 경우, 비슷한 Content가 없는 Unpaired된 dataset 상황에서 불필요한 정보가 전달되어 Model 성능이 저하되었다고 보고 있습니다
Results of Attribute Controlled Image Translation

PONO can improve the performance of MUNIT
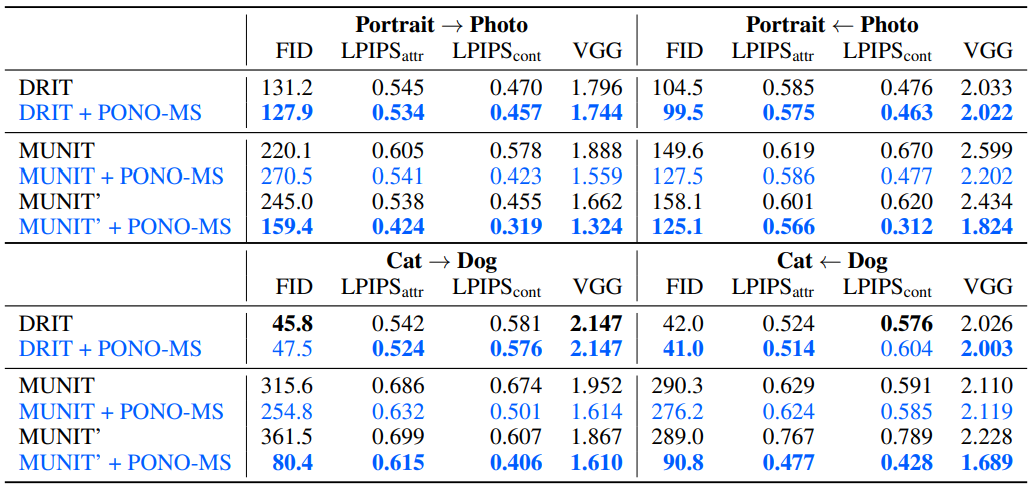
- Portrait/Photo dataset의 경우, DRIT과 MUNIT의 비교에서 MUNIT이 parameter가 더 많음에도 더 낮은 성능을 보였습니다
- MUNIT 자체가 해당 dataset에 맞게 디자인되지 않은 것을 원인으로 보고 있습니다(데이터 수, image resolution의 차이)
- Data간 Align이 잘되어있는 AFHQ dataset의 경우, MUNIT에서 비약적인 성능 향상을 보였습니다
- Conv3x3-LN-ReLU를 추가한 MUNIT이 비선형성을 증가시켜 더 좋은 성능을 재연해냈습니다.
- 기존에는 Output Layer와 input 사이에 feature statistic을 re-introduce하는 Layer가 1개밖에 없었습니다