진행기간: 2021.03 ~ 진행 중
주요내용: 사용자의 고유 창작물을 Stylize해주는 스케치 스타일링 Tool 개발
기여한 점: Sketch Stylization Model 제작, 기존 Unsupervised Image-to-Image Translation Baseline Model에 Positional Normalization 적용하여 모델 성능 향상, Style Mixing 기능을 적용하여 다채로운 Style 표현, Flask를 이용한 Pytorch 모델 배포
사용한 Skill 또는 지식: Pytorch, Flask, Unsupervised Image-to-Image Translation
Table of contents
Image Translation

Image Translation 모델을 개발하고 본 모델을 활용한 어플리케이션을 제작하였습니다. Image translation이란 특정 domain의 이미지를 다른 domain의 이미지로 바꾸는 작업을 의미합니다. Image translation을 활용한 어플리케이션으로 동물의 종을 변화시키는 Animal translation(horse2zebra), Label map을 실제 사진으로 만드는 Semantic Image Synthesis(SPADE) 등이 있습니다. 이번 포스트에서는 Sketch 이미지를 painting 이미지로 변환하는 Image Translation 모델 제작 과정을 공유하고 이를 서비스로 구체화시키며 느낀 경험에 대해 이야기하고자 합니다
Problem Statement
- Style Transfer
- pre-trained 네트워크를 이용한 영상 최적화 방식
- 새롭게 합성될 영상의 feature map이 Content/Style Image로부터 나온 feature map과 비슷한 특성을 갖도록 근사
- GAN
- 이미지 데이터의 확률 분포를 근사하는 모델 학습 방식
- 특정 Domain의 데이터를 다른 Domain의 데이터로 변환하는 Mapping Funtion 학습
- Sampling을 통해 실존하지 않지만 있을 법한 이미지 생성
Sketch를 Painting으로 바꿔주는 Image Translation 모델은 이미지 생성 방식에 따라 두 분류로 나눌 수 있습니다. Style Transfer를 이용한 방식과 GAN을 이용한 방식이 그 예입니다. Style Transfer의 경우, pre-train 네트워크를 이용한 영상 최적화 방식으로 새롭게 합성될 영상의 feature map이 Content/Style Image로부터 나온 feature map과 비슷한 특성을 갖도록 근사합니다. 반면, GAN의 경우 특정 Domain 데이터의 확률 분포를 근사하는 모델 학습 방식으로 다른 Domain의 데이터로 변환하는 Mapping Function을 학습합니다. 두 방법은 이미지 자체에서 optimization을 진행하는지 혹은 Domain별 데이터의 확률분포를 바탕으로 optimization 진행하는지에 따라 차이를 보입니다
기존 Style Transfer의 문제점
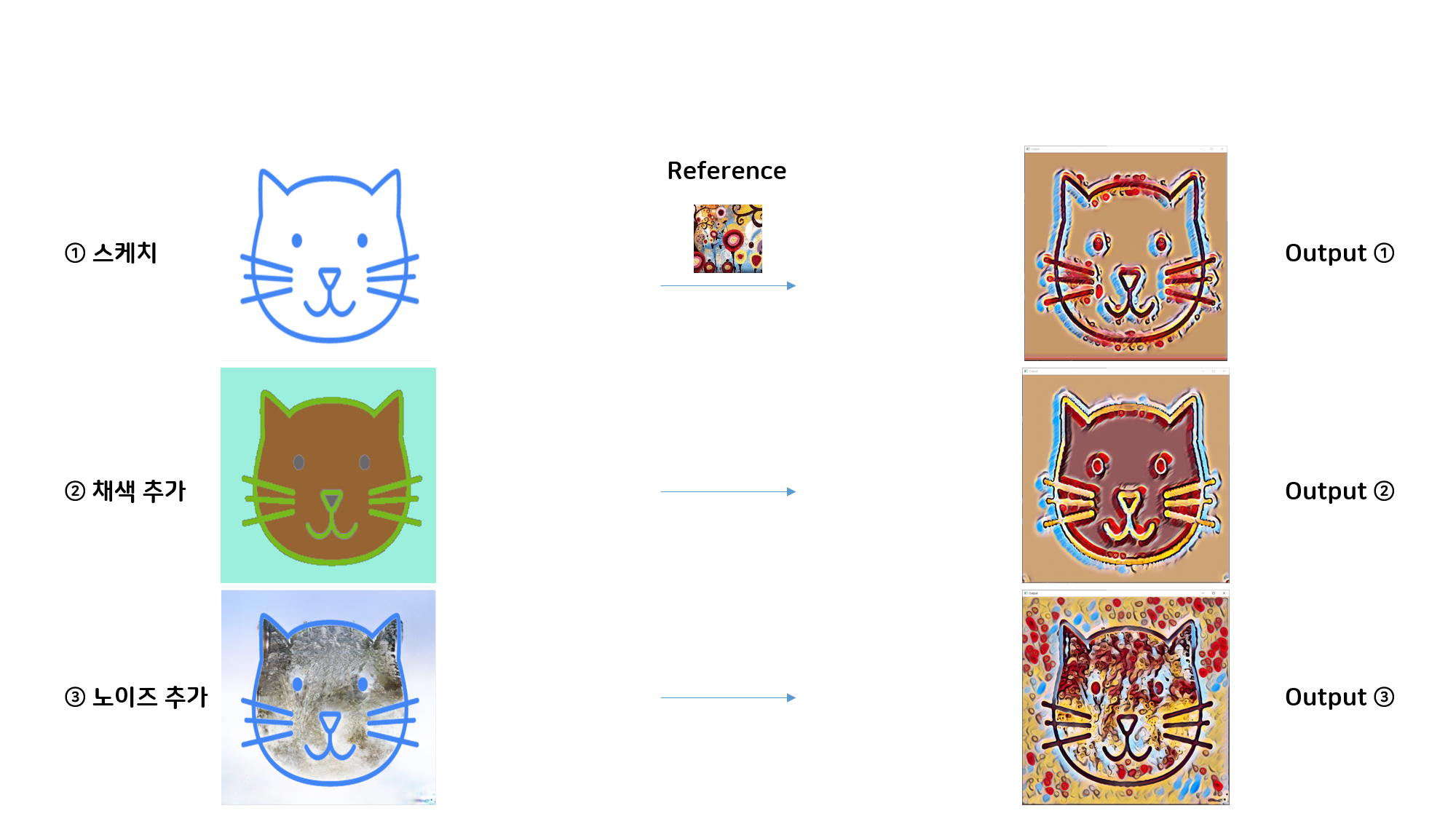
일반적으로 Photo-realistic 이미지를 대상으로한 Style Transfer 모델은 Sketch 이미지에 대해 효과적으로 Stylize 할 수 없는 것을 발견했습니다. Sketch 이미지의 경우 그리고자 하는 Object의 정보가 많지 않아 여백 공간에 Style이나 Color를 단순하게 Mapping하는 문제가 발생했습니다. 이는 추가로 실험한 스케치+채색, 스케치+노이즈 케이스를 통해서 보다 명확히 이해할 수 있었습니다.
Visualize Photo/Sketch Feature Map
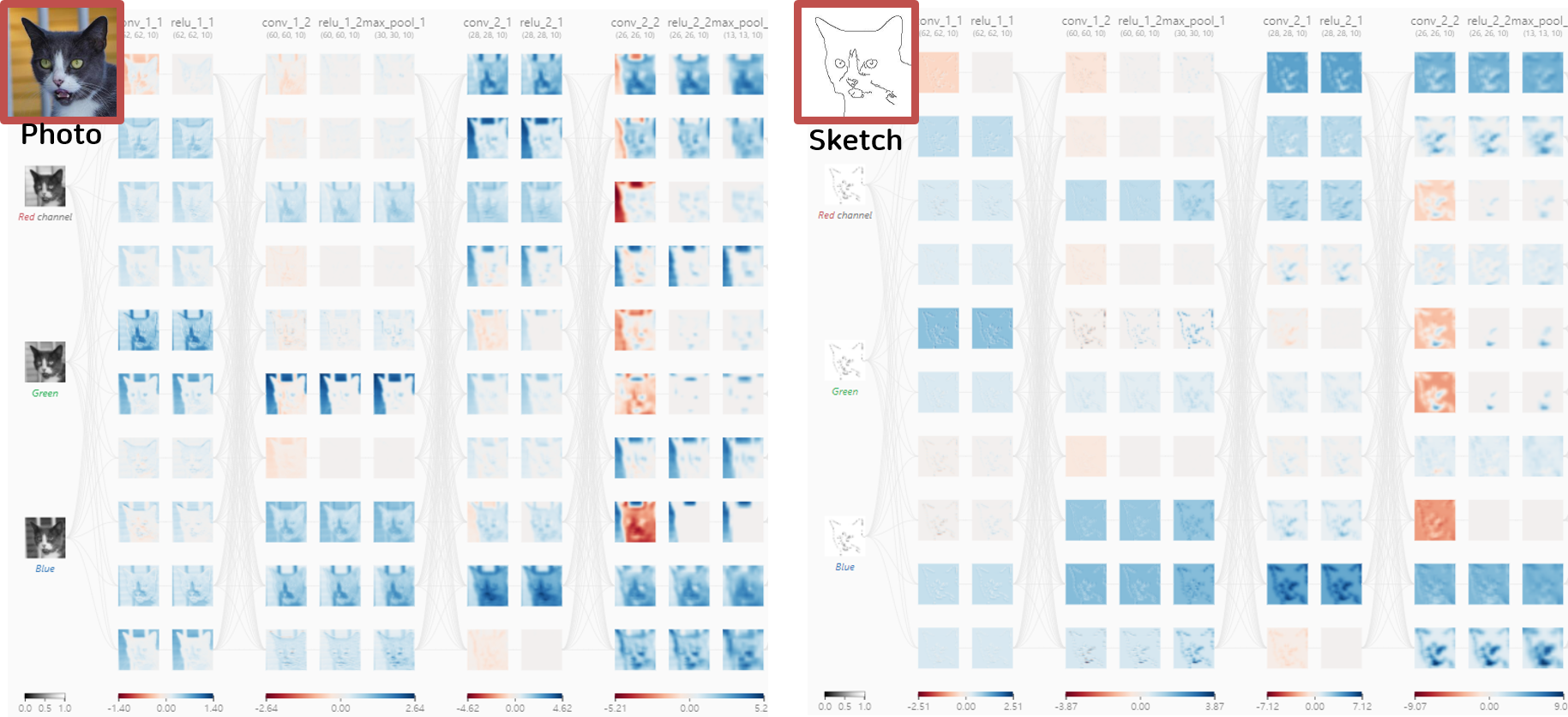
Photo-realistic 이미지와와 Sketch 이미지의 Feature Map을 시각화한 결과입니다. 일반 사진의 경우, 고양이 객체 뿐만아니라 이미지를 구성하고 있는 배경에서도 다양한 요소가 활성화 되어있습니다. 반면, Sketch 이미지의 경우, Edge line 주변에서 활성화 되거나 활성화 되는 부위가 없거나 Edge line을 제외한 모든 영역이 한번에 활성화되는 것을 볼 수 있습니다. 이는 기존 Feature Map Optimize 방식인 Style Transfer가 Sketch 이미지를 효과적으로 Stylize할 수 없다는 것을 뜻합니다.
실험 결과에 따라 Sketch 이미지 적절하게 Stylize하기 위해 GAN을 이용한 Image Translation 모델을 사용했습니다. AFHQ Dataset의 고양이 이미지로부터 Domain A는 Sketch 이미지로, Domain B는 Stylized된 이미지로 구성하여 모델학습을 진행했습니다. 지금부터는 학습에 필요한 데이터 전처리 과정과 모델 학습 과정에 대해 다루도록 하겠습니다.
Data Processing
일반적으로 많이 알려진 Sketch Dataset으로 Sketchy Database, TU-Berlin 등이 공개되었으나, class 단위로 추산했을때 Image Translation 모델이 최소 성능을 보장할 만큼 데이터의 양이 충분하지 않았습니다. 또한 일반 사진 이미지에 Canny Edge Detection을 수행할 경우, 사진의 배경이 같이 검출되어 특정 Class 대한 Sketch를 확보하기 어려웠습니다. 이를 해결하고자 Segmentation Network(DeepLabv3)를 활용하여 일반 사진으로부터 특정 class에 대한 Sketch 이미지를 확보하였습니다. 이번 목차에서는 Sketch data확보에 필요한 Data Processing 절차에 대해 이야기하고자 합니다


1.Sketch Object 선정
특정 Class의 Object 사진을 얻기 위해, Semantic Segmentation Network로부터 얻고자하는 class 지정합니다. 이를 통해 이미지에서 특정 class의 pixel만 검출해내는 binary Segmentation map 확보합니다.
2.Background 이미지 제거
앞서 확보한 binary Segmentation map을 Mask 이미지로 사용하여 Element wise Product를 통해 background 이미지를 제거합니다

3.흑백 반전
스케치 특성을 반영한 이미지를 만들기 위해 흑백 반전(cv2.bitwise_not)을 수행합니다.


4.Guassian blur와 Canny Edge Detection
Guassian blur를 통해 노이즈를 제거하고 Canny Edge Detection의 파라미터 조절하여 윤곽선을 검출합니다.
5.이미지 Dilation
이미지 Dilation을 통해 굵기가 가는 Edge line을 굵게 변형함으로써 실제 사용자 Sketch와 가깝도록 수정하였습니다
6.공백 이미지 제거

공백 이미지가 학습 데이터에 포함될 경우, 모델학습시 Input Tensor가 NaN or INF가 됩니다. Input Tensor가 Nan(or Infinite)이 될 경우, backpropagation 과정에서 문제가 발생하여 모델이 Blackout되는 현상이 나타납니다. 따라서 전처리 과정에서 Sketch data중 NaN or INF 이미지가 없는지 검증하는 절차가 필요합니다.
7.최종 Sketch dataset 확보
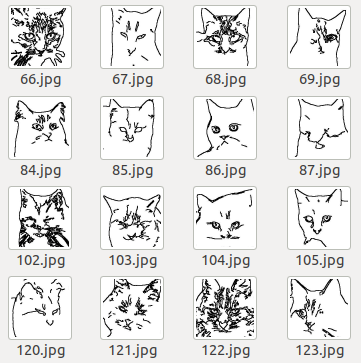
6번까지의 전처리 과정을 통해 최종적으로 학습에 필요한 고양이 Sketch 이미지 4천장을 확보할 수 있었습니다
Model Training
Multimodal Unsupervised Image-to-Image Translation
사용자가 하나의 Input Sketch에 대해 다양한 Stylized 결과물을 선택할 수 있도록 Multi-Modal image translation의 MUNIT을 baseline 모델로 사용하였습니다. 기존의 Deterministic 모델의 한계을 넘어선 MUNIT은 이미지의 representation을 content space와 style space로 분해하여 한가지 input에 대해 다양한 output을 얻을 수 있도록 One-to-Many mapping을 지원합니다.
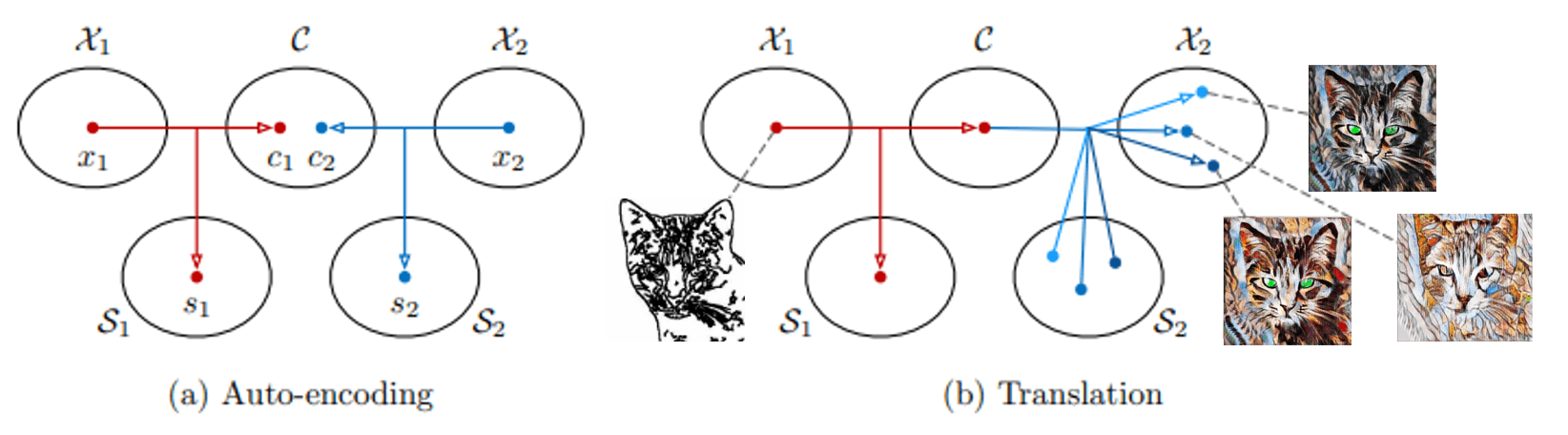
Auto-encoding
- content space는 서로 다른 도메인 사이에서 공유되는 domain-invariant한 정보로 두 도메인의 underlying structures(content)를 포착합니다
- ex) the head pose of the animal
- style space는 각 도메인마다 존재하는 domain-specific한 정보로 특정 도메인의 texture나 color같은 style distribution을 포착합니다
- style distribution은 가우시안 분포를 띄는 vector로 간주하여 random sampling을 통해서도, user의 reference image를 통해서도 추출이 가능합니다
Translation
- Input 이미지를 target domain의 이미지로 변환하기 위해 content code를 추출합니다
- 변환시 Input 이미지의 content 정보는 보존되며 style 정보는 변경되어야 합니다
- Target domain의 style distribution으로부터 style code를 sample 합니다
- 서로 다른 style code를 sampling함으로써 Input content에 대한 다양한 스타일의 output을 조합할 수 있습니다
Loss Function
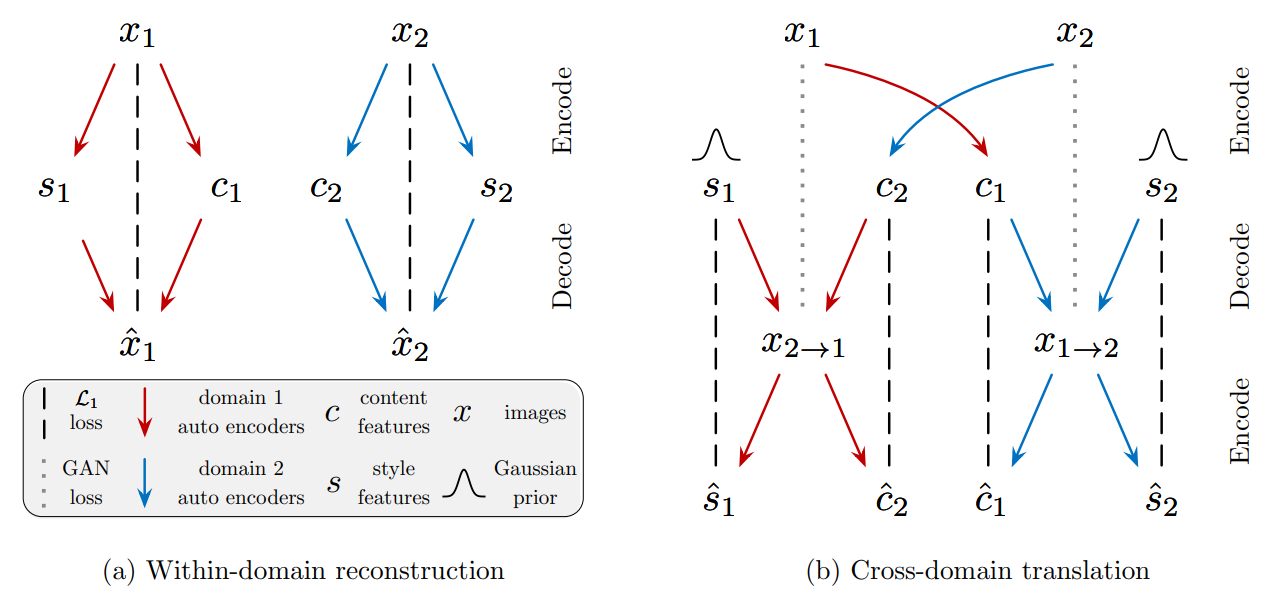 gray dotted lines : enforce two image distributions to be the same
gray dotted lines : enforce two image distributions to be the same
- Bidirectional Reconstruction Loss
auto-encoder가 이미지 reconstruction과 latent coding을 수행하도록 loss를 설정합니다.- Image Reconstruction (Image -> latent -> Image)
- 일반적인 auto-encoder의 학습 과정과 같습니다
- 원본 image를 복원하기 위해 encode, decode 과정을 거치고 Input과 Output이 같도록 유도합니다
- latent reconstruction loss for the Content/Style code (latent -> Image -> latent)
- 이미지를 latent code로 encode 시킨 뒤, Cross-domain으로 latent code를 decoding 합니다
- 결과 이미지를 다시 latent code로 encoding하여 original latent code와 같도록 유도합니다
- Image Reconstruction (Image -> latent -> Image)
- GAN Loss
- output 이미지가 target domain dataset의 distribution과 같도록 제약을 걸어줍니다
- output 이미지가 실제 target domain의 이미지 같도록 도와줍니다
Style-augmented Cycle Consistency
Joint distribution matching은 unsupervised Image-to-Image translation을 위한 중요한 제약사항입니다. 하지만 이 제약사항을 너무 강하게 강제하면 model이 deterministic function이 됩니다. Multi-modal Image Translation을 위해서는 cycle consistency를 다소 느슨하게 할 필요성이 있습니다. MUNIT에서는 image를 target domain으로 translation한 뒤, 다시 translate back하는 과정에서 original style code를 사용함으로써 target image가 다시 original image가 되도록 Bidirectional Reconstruction Loss에 설계되었습니다.
Model Architecture
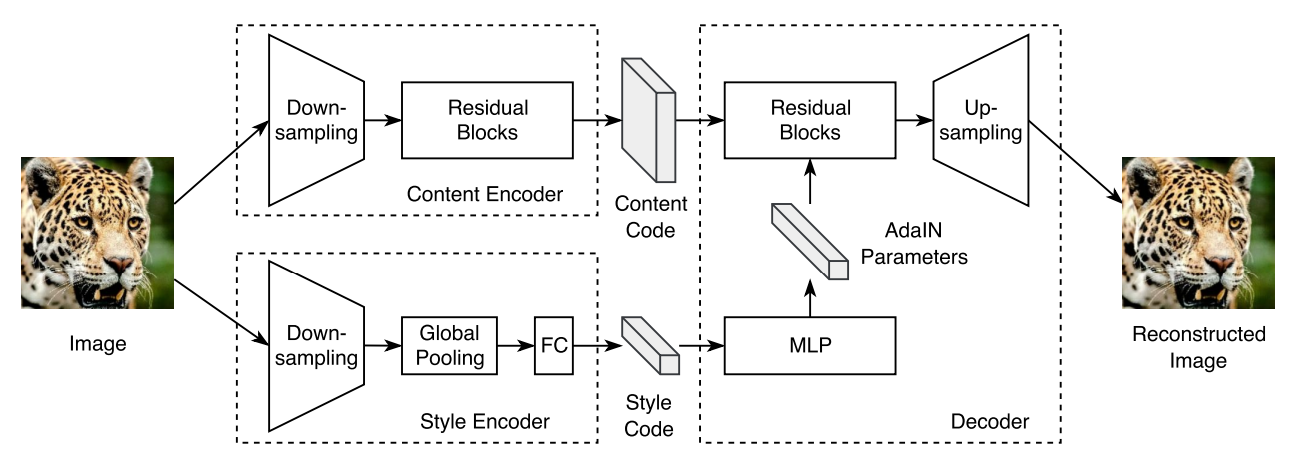
- Content Code : Domain간 common structure를 나타내는 2D feature maps을 나타냅니다
- Style code : global style 정보가 담겨있는 1D feature vector를 나타냅니다
- AdaIN : Stlye을 결정하는 Affine 파라미터입니다. 이미지 합성시 Style code로부터 affine 파라미터를 구해 target 이미지를 Reconstruction 합니다
- MLP : AdaIN에 사용될 파라미터를 결정합니다
Model Architecture 외 특이한 사항으로는 Image Synthesis에 많이 사용되는 Instance Normalization 대신 Layer Normalization이 사용됐다는 점이 있습니다. Instance Normalization의 경우 채널 각각을 normalize하여 채널간 유기적인 정보를 파괴해 적절한 스타일이 반영되지 않은 결과를 나타냈습니다. 따라서 채널을 같이 Normalize하는 Layer Normalization을 사용함으로써 채널간 유기적인 관계를 유지하고 Content에 대해서 채널축마다 스타일을 성공적으로 합성시킬 수 있었습니다.
PONO
Positional Normalization 기법을 통해 기존 baseline model의 성능을 향상시켰습니다. Pixel position별 Feature 차원의 정규화를 수행하는 PONO는 네트워크가 Structural한 정보를 쉽게 파악하도록 도움으로써 GAN에 적용했을 때 Image Generation 성능을 크게 향상시키는 것으로 나타났습니다. 해당 기법에 대한 자세한 설명은 Positional Normalization 포스트에 작성하였습니다.
Model Serving
Flask를 이용하여 PyTorch 모델을 배포하고 Inference 할 수 있는 REST API를 만들었습니다. Image Translation 모델을 위한 웹 API를 작성하여, 그림판 내부에서 스케치를 Stylize하는 웹 서비스를 만들 수 있었습니다. Model Serving을 위해 다음과 같은 내용들을 학습할 수 있었습니다.
- 학습한 PyTorch 모델을 Flask 컨테이너로 감싸고 웹 API로 노출하는 방법
- 웹 요청(request)을 모델에 입력하기 위한 이미지 전/후처리
- 모델의 결과를 HTTP 응답(response)로 패키징하는 방법
API 엔드포인트(endpoint)의 요청(request)와 응답(response)을 정의
@app.route('/api/stylize', methods=['POST'])
def stylize():
style_number = int(payload['style'])
image_file = request.files['contentImage']
try:
output_buf = internal_stylize(image_file, style_number)
output_buf = io.BytesIO(output_buf)
output_buf.seek(0)
return send_file(
output_buf,
)
except Exception as ex:
print('�~W~P�~_�!', ex)
1.Endpoint 경로를 /api/stylize로 지정 후, 이미지 파일은 POST 요청에 허용하도록 합니다.
2.이미지 파일을 모델 Inference를 위한 인자로 특정 Style 번호와 함께 보냅니다.
Inference
transform = transforms.Compose([transforms.Resize((new_size,new_size)), transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
def internal_stylize(image_file, style_number):
with torch.no_grad():
image = Variable(transform(Image.open(image_file).convert('RGB')).unsqueeze(0).cuda())
# Start testing
content, _ = encode(image)
style_rand = Variable(torch.randn(opts.num_style, style_dim, 1, 1).cuda())
style = style_rand
for j in range(opts.num_style):
s = style[j].unsqueeze(0)
outputs = decode(content, s)
outputs = (outputs + 1) / 2.
path = os.path.join(opts.output_folder, 'output{:03d}.jpg'.format(j))
vutils.save_image(outputs.data, path, padding=0, normalize=True)
3.모델 Inference를 위해 일련의 transforms 세트를 구성합니다. 이미지 파일의 크기를 resize하고, 텐서로 변한한 뒤, 정규화를 적용합니다. 이후, 모델 Inference를 진행하여 Stylized된 결과물을 서버 스토리지에 저장합니다.
Post-Processing
transfer = outputs.data.clamp(0, 1)
transfer = torch.squeeze(transfer)
transfer = transfer.cpu()
res = transforms.ToPILImage()
res = res(transfer)
res_resize = res.resize((512, 512))
buf = io.BytesIO()
res_resize.save(buf, format='JPEG')
return buf.getvalue()
4.Stylized 결과물을 Tensor에서 PIL로 변환하기 위해 transforms.ToPILImage()를 사용합니다. 또한 작업 결과물을 buffer에 byte 모드로 저장하고 이를 반환하도록 합니다
Prototype
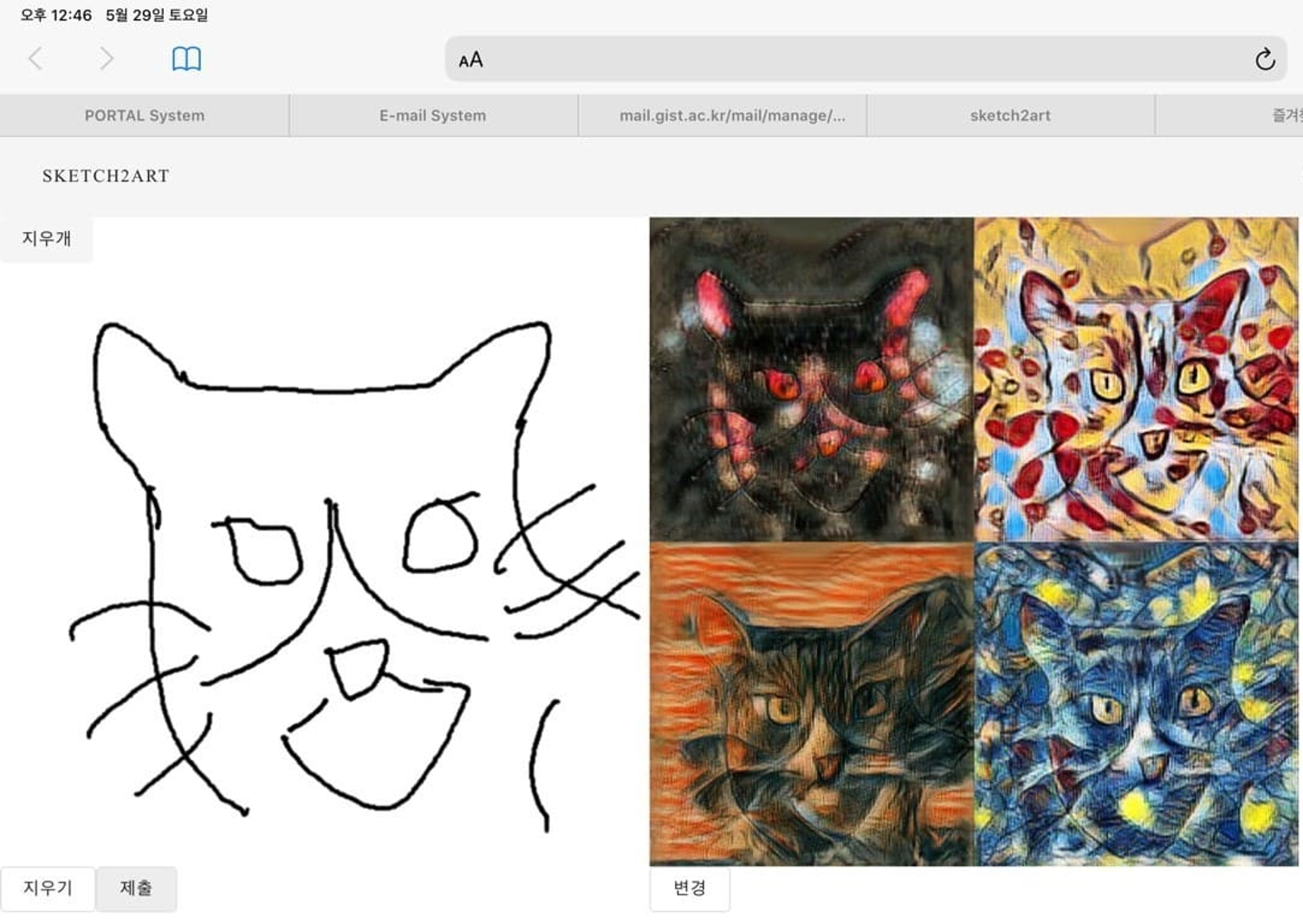
Future Work
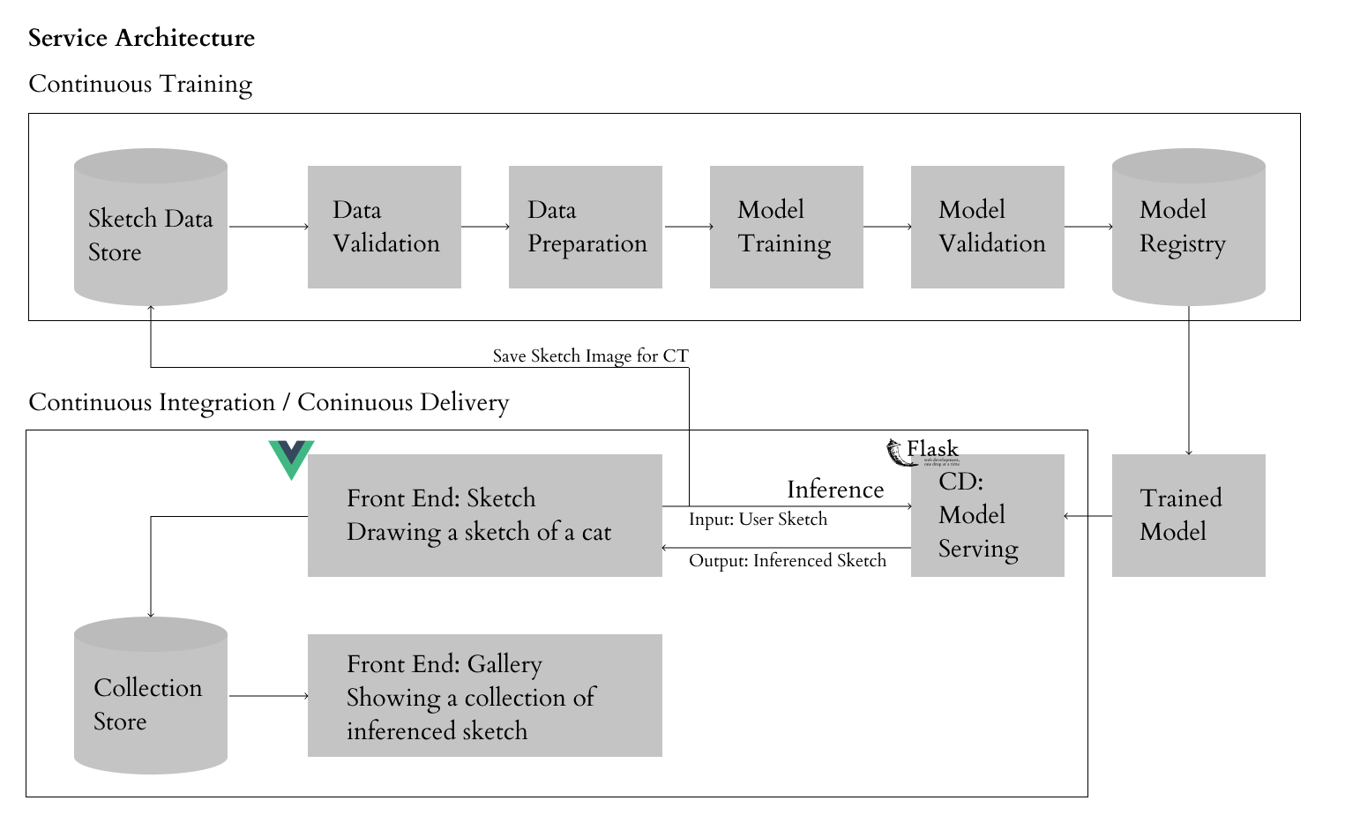
실제 사람이 그린 Sketch 이미지는 사진의 Edge 이미지와 다른 형태적 특성을 가지고 있습니다. 이를 개선하고자, 사람들이 그린 Sketch 이미지를 모델 학습에 반영하는 MLOps 파이프라인을 구축 중에 있습니다. 데이터 기반으로 지속적인 CI/CT/CD 환경을 만들어 모델 성능을 향상시키고 서비스의 사용성을 높이고자합니다. 더불어, 온라인 전시 공간 마련을 통해 누구나 손쉽게 ML Art를 접할 수 있는 Gallery를 제작하고자 합니다. 작품과 공간이 조화롭게 구성된 Gallery를 통해 사용자가 조금 더 몰입감이 높은 분위기에서 작품을 감상할 수 있도록 구상하고 있습니다
Reference
[1] Image-to-Image Translation and Applications
[2] Visualization and Interpretability
[3] CNN 시각화 사이트
[4] Style Transfer
[5] FLASK를 이용하여 PYTHON에서 PYTORCH를 REST API로 배포하기
[6] FLASK로 배포하기
[7] io — 스트림 작업을 위한 핵심 도구
[8] 이미지 읽는 방법 / cv.imdecode( ), io.BytesIO( )
[9] OpenCV image 또는 PIL image와 BytesIO 연동
[11] MUNIT
[12] PYTORCH 모델을 ONNX으로 변환하고 ONNX 런타임에서 실행하기
[13] AI Production Roadmap - AI 시스템의 요구사항과 기술의 방향