Table of contents
Abstract
- 기존 I2I model은 multiple target instances를 변환하거나 Geometry Change를 크게하는 task에 대해 어려움을 겪고 있음
- Instagan은 이미지와 instance 정보(object segmentation mask)를 활용하여 multiple target instances, Geometry Change에 대한 변환을 시도
- Segmentation masks를 이용하여 instance를 변환하기 위한 필요 조건과 네트워크 구조 제시
- 네트워크가 instances와 background를 구분할 수 있도록 돕는 Context preserving loss 제안
- Sequential mini batch training기법을 통해 multiple instances에 대한 일반화 성능을 높이고 제한된 GPU로 효율적으로 학습할 수 있는 방법론 제안
Datasets

- 객체 탐지(object detection), 세그먼테이션(segmentation), 키포인트 탐지(keypoint detection)에 사용되는 MS COCO Dataset 사용
- 이미지 한장마다 여러 장의 instances segmentation mask가 함께 존재하고 Edge line이 선명하며 Pixel Intensity가 확실한 것이 특징
Architecture
CycleGAN과 다른 점
- Instagan은 additional한 instance정보를 활용한다는 점에서 기존 I2I 와 차이가 있음
- attribute augmented space(XxA, YxB)간 joint mapping을 학습하는 방식
- 본 방식은 G가 서로 다른 domain의 instance 정보를 더 잘 disentangle하고 정확하고 섬세한 변환을 도움
- cycleGAN과 다르게 single mapping만으로도 학습이 가능함
- 기존의 경우 cycle loss(Gyx(Gxy(x)) ~ x)를 통해 2개의 mapping function(Gxy, Gyx)를 jointly하게 학습
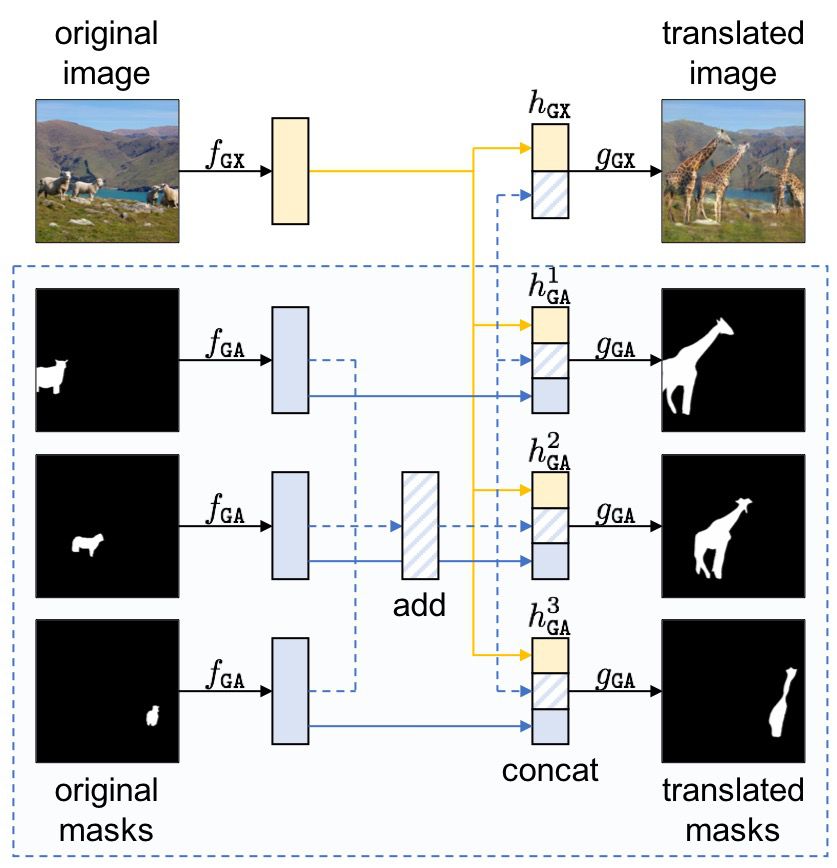
Generator
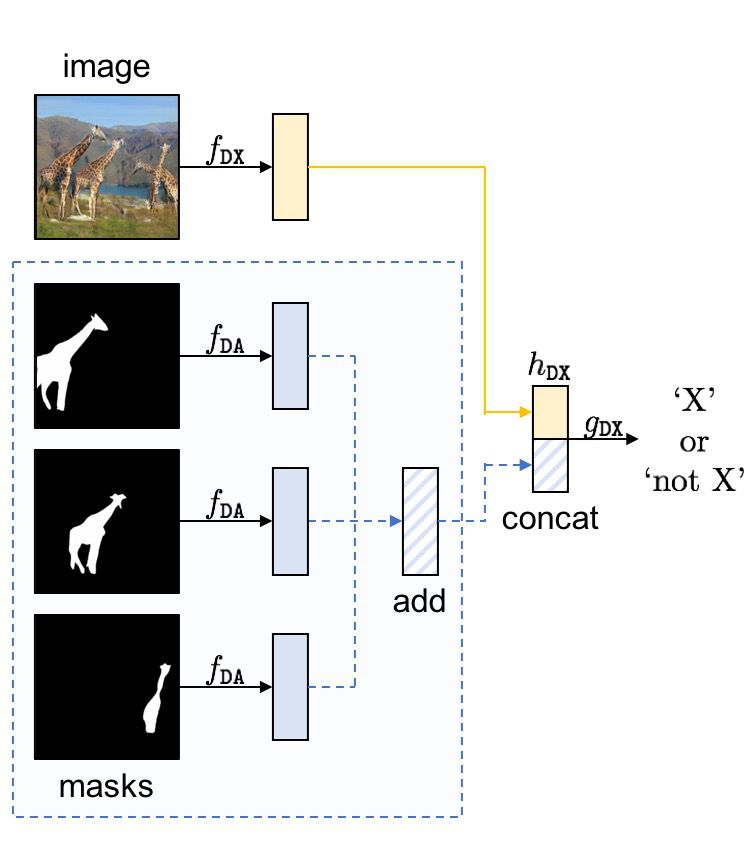
- 이미지 x와 segmentation a를 Encode하여 target domain의 이미지 y’과 segmentation b’을 변환
- 여러 instance의 segmentation 이미지를 Image translation에 활용하기 위한 조건
- y’은 a에 있는 각각의 instance에 대해
Permutation-invariant 성질을 띄어야 함
- Input 벡터 요소의 순서와 상관없이 같은 출력을 생성하는 모델
- b’은 a에 있는 각각의 instance에 대해
permutation-equivariant 성징을 띄어야 함
- input이 바뀌면 output이 동일한 방법으로 바뀌는 것
- Feature encoding
- Image feature extractor fgx와 attributes feature extractor fga를 각각 사용
- 여러 개의 instance mask 이미지는 Attribute feature extractor에 의해 feature가 추출되고 이를 aggregation 하여 permutation invariant 한 feature set 구성
- Image와 attribute feature를 concat하여 G에 전달
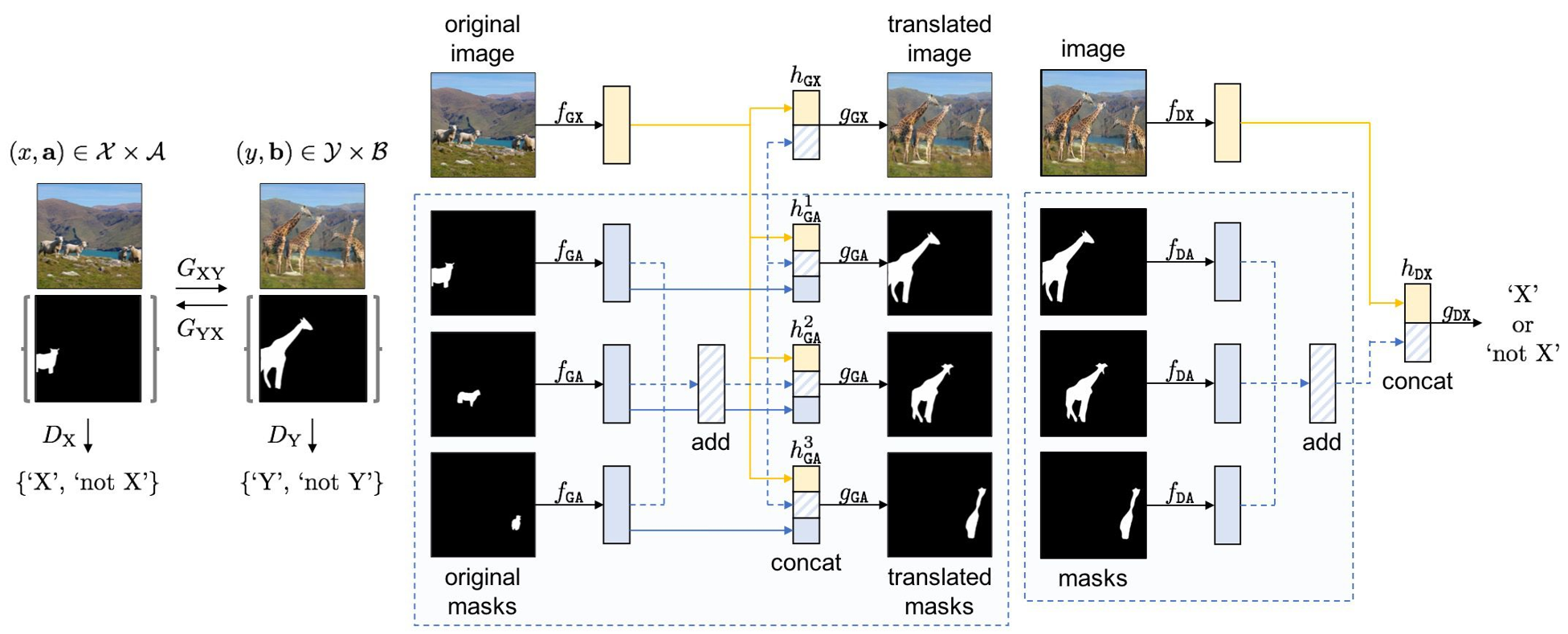
Discriminator
- 이미지 x와 segmentation a를 Encode하여 해당 정보가 원본 Domain의 것인지에 대한 판별 진행
- Segmentation은 Discriminator에 대해 permutation invariant 성질을 충족해야함
- Discriminator에서 이미지 x와 segmentation a를 처리하는 feature extractor를 나눈 뒤 두 정보를 joint 하게 학습
- 이미지 x와 segmentation a의 관계성을 학습하도록 도움
- Generator와 Discriminator에서 x와 a를 joint 하게 학습시킴으로써 Generator가 target segmentation mask에 맞는 image instance를 잘 생성할 수 있음
Training Loss
- I2I Loss 설계시 변화시켜야할 것과 유지해야할 것을 명확히 정의해야 됨
- 변화시켜야 하는 것 : instance의 shape와 style을 target domain의 특성에 맞게 변화시켜야함
- 유지되어야 하는 것 : 원본의 background 혹은 instance’s domain independent characteristics
- Domain loss로는 일반 GAN Loss 사용
- 생성된 이미지가 target domain 의 style을 따르도록 유도
- Content loss로 Cycle consistency loss, Identity mapping loss 사용
- 이미지 변환시 생성된 이미지가 원본의 content를 잃지 않도록 유도
- Context preserving loss
-
\[L_{ctx} = \lVert \omega(a,b^\prime) \odot (x-y^\prime)\rVert_1 + \lVert \omega(b,a^\prime) \odot (y-x^\prime) \lVert_1\]
- Background를 유지한 채, instance만 변화되도록 유도
- Image translation시 instance의 segmentation 영역이 달라져, 두 이미지에서의 background 정의가 달라지는 문제 발생
- Source 이미지와 Translated 이미지에서 공통으로 background 라 정의된 부분만 배경으로 정의
- real_A_seg와 fake_B_seg 를 더해 새로운 segmentation map 을 만든 후 값을 반전
- background : 1, instance: 0
Sequential Mini-Batch Translation
- Multi instance에 대해 한번에 backpropagation을 진행할 경우 많은 GPU memory가 요구됨
- 제한된 메모리로 다수의 instances를 처리할 수 있도록 새로운 inference/training technique 제시
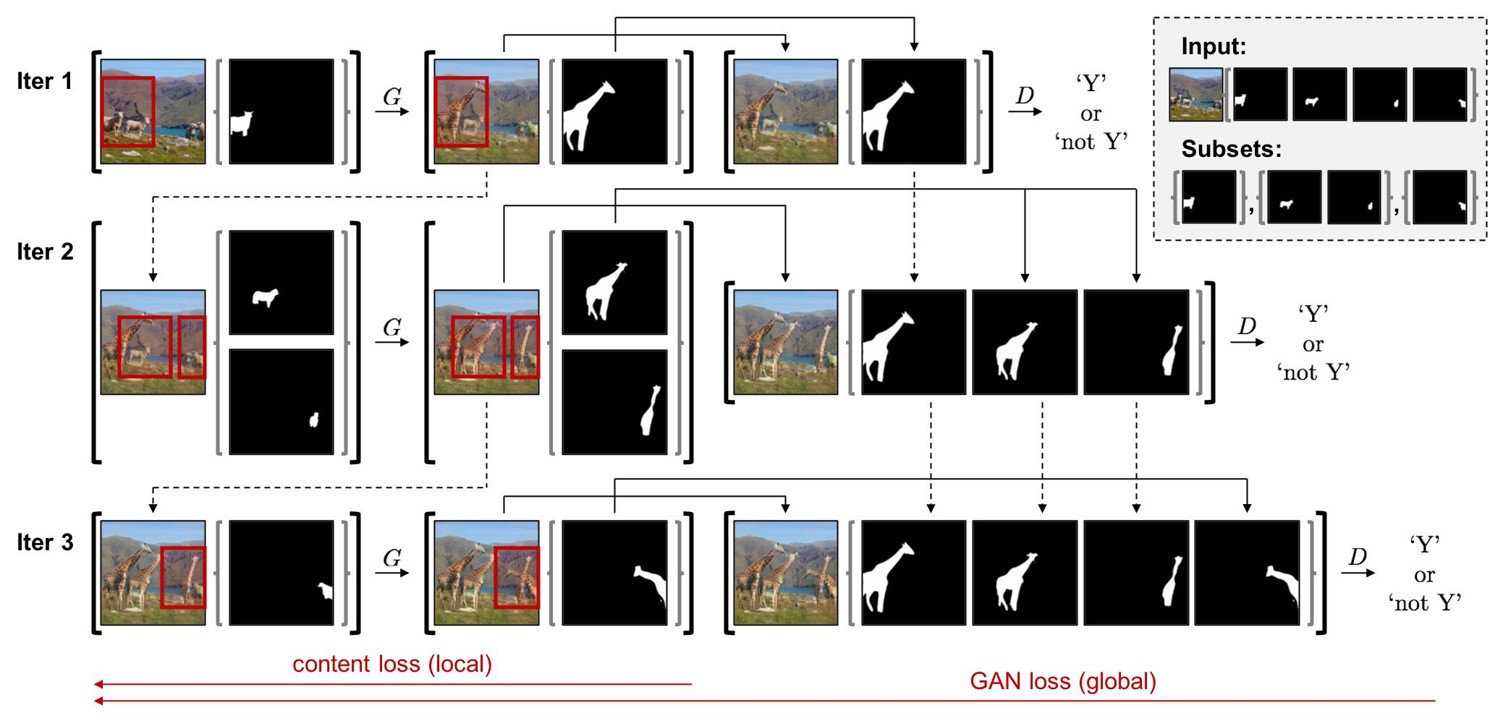
- Instance segmentation mask들을 N개의 mini batch로 나누고 N번의 iteration을 순차적으로 실행
- 마지막 N번째 iteration에서만 backpropagation을 수행하여 GPU 메모리를 절약
- Translated된 y’과 aggregated segmentation 이미지 b’을 가지고서 GAN loss 수행
- Instance의 segmentation 이미지를 부분적으로만 사용할 경우, 네트워크가 Image와 Mask 이미지를 align하는 것에 실패함
- Permutation-invariant 특성으로 Iteration을 여러 번 수행하는 과정을 통해서 data augmentation 효과를 얻을 수 있었음
- Segmentation mask를 한번에 사용하는 One step approach에 비해 더 좋은 일반화 성능을 보임